
This blog aims to provide a basic understanding of GPUs for ML/MLOps Engineers, without going into extensive technical details. The focus will be on developing a broad knowledge of GPUs to aid in hardware decision-making for managing ML/DL workloads and pipelines. This blog will not include comparisons of different GPU architectures for ML workloads.
Before we begin, let’s review some key terminologies that will be used throughout this blog:
- Latency: The time delay between the initiation of a task and the detection of its effects.
- Throughput: The amount of work completed within a given timeframe.
- FLOPS: Floating-Point Operations Per Second, used to measure the computing performance of the ALUs.
- Device: A GPU consisting of multiple multiprocessors.
- Device memory: The VRAM of a GPU.
- Host: The CPU of the system on which the GPU is installed.
- Multiprocessor: A set of processors and shared memory within a GPU.
- Kernel: A GPU program used to execute tasks (not to be confused with the Linux kernel).
- SIMD: Single Instruction, Multiple Data units, which perform the same operation on multiple data operands simultaneously and are commonly found in GPUs.
- GP-GPUs: General-Purpose Graphics Processing Units, which can be used for a range of tasks beyond graphics processing.
- CUDA: Compute Unified Device Architecture, a programming model and parallel computing platform for general computing on GPUs.
- ALUs: Arithmetic Logic Units, which carry out arithmetic and logic operations on the operands in computer instruction words.
- Cache: A smaller, faster memory located closer to a processor core that stores copies of frequently used data from main memory locations.
- Registers: Small amounts of data, computer instructions, or storage addresses that hold information.
- Clock speed: The number of cycles that the processor executes per second.
What is a GPU
A GPU, or Graphics Processing Unit, was originally designed to handle specific graphics pipeline operations and real-time rendering. However, GPUs have since evolved into highly efficient general-purpose hardware with massive computing power. This has led to their increased usage in machine learning and other data-intensive applications.
The initial GPUs were designed with fixed functions to handle specific pipeline stages, as shown in the following diagram:
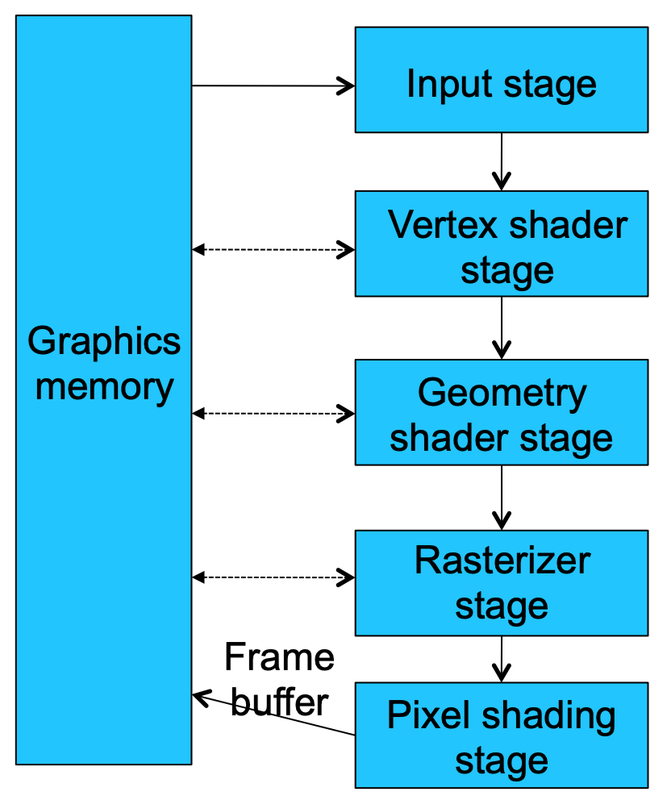
A simplified architecture of early GPUs is shown below: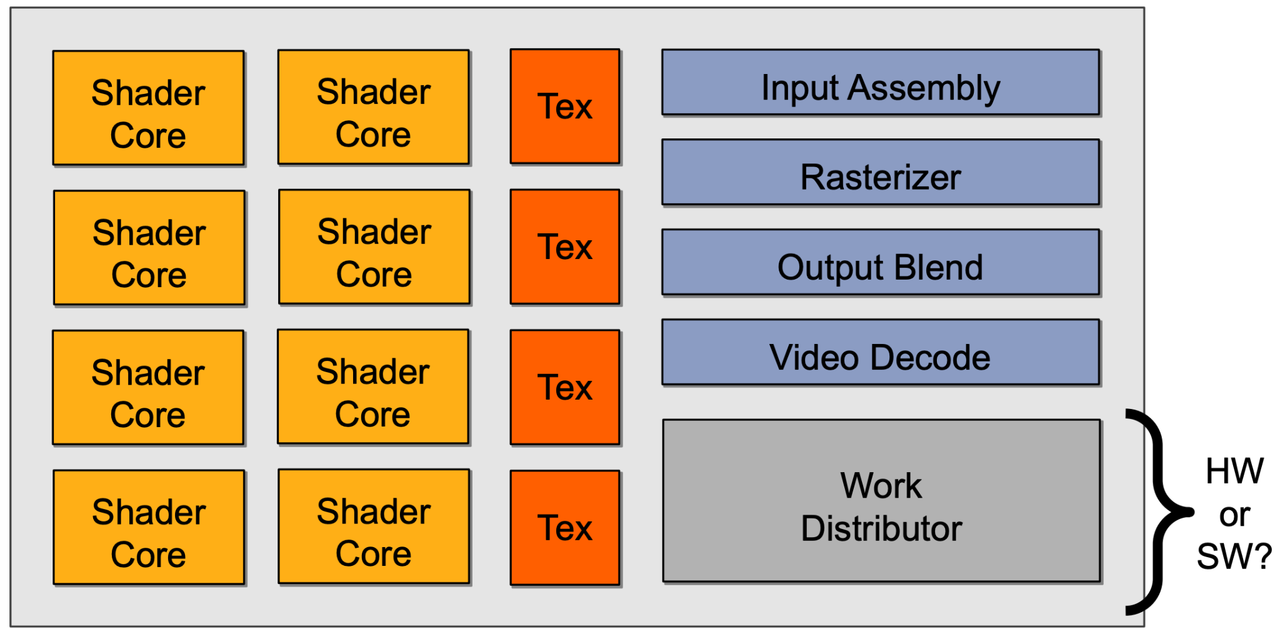
Each fixed function the GPU performed had dedicated API calls that were implemented in hardware. To use GPUs for computational workloads, tasks had to be mapped to the computer graphics domain. Early GPUs used graphics languages like OpenGL, but this approach was not scalable for problem domains that didn’t map well to computer graphics.
This led to the development of general-purpose GPU (GP-GPU) architectures and corresponding programming models like CUDA, CAL, and OpenCL. Modern GP-GPUs have high FLOPS, with the NVIDIA A100 delivering up to 312 teraFLOPS. They also offer programmability, unlike early GPUs which were focused on integer arithmetic and lacked instruction sets and memory for high throughput.
GP-GPUs are programmable processors, and they have memory and instruction sets designed to handle high throughput of floating-point arithmetic operations. They are highly parallelizable, with thousands of cores per device that are organized into multiprocessors. Each multiprocessor consists of multiple processors and shared memory. A kernel is a GPU program that is executed by a multiprocessor.
GP-GPUs use Single Instruction, Multiple Data (SIMD) units to perform the same operation on multiple data operands concurrently. They also have caches and registers to hold frequently used data or instructions, which reduces memory latency.
Overall, GP-GPUs have evolved from their initial purpose of handling graphics pipeline operations to become powerful hardware for data-intensive applications. Their massive computing power and programmability make them a valuable tool for ML/MLOps engineers managing ML/DL workloads and pipelines.
Hardware Components
To understand the hardware components of GPUs, we need to understand the hardware components of the CPU first.
CPU Hardware
A Central Processing Unit (CPU) is the primary component of a computer system that executes instructions of a program.
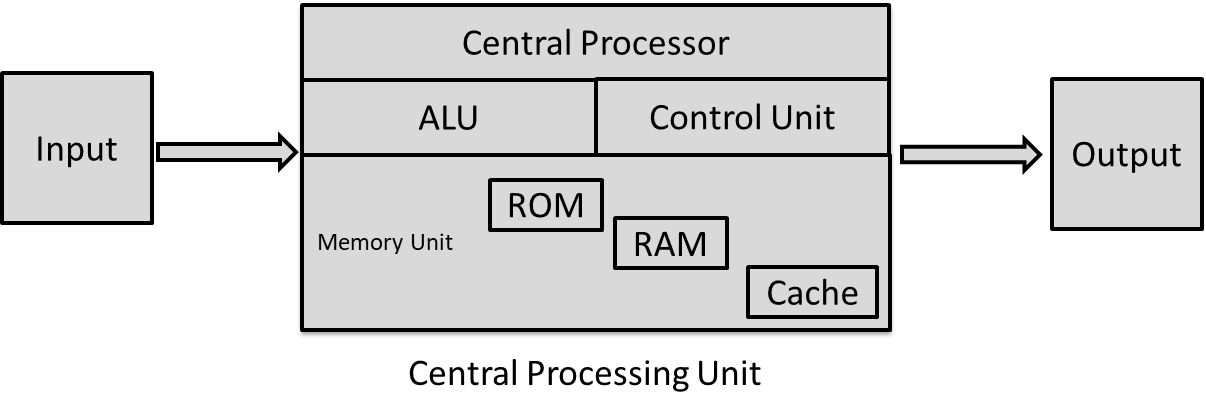
It has the following components:
-
Arithmetic Logic Unit (ALU): The ALU performs the arithmetic and logical functions of a CPU. It is responsible for performing calculations such as addition, subtraction, and comparison operations.
-
Registers: Registers are used to store data temporarily during and after operations. They are used to facilitate data movement between different components of the CPU.
-
Control Units: Control units are responsible for managing the execution of instructions. They decide which instruction to execute and then which data to pick up and send to the ALU for execution.
-
Cache: The CPU uses cache memory to store frequently accessed data and instructions closer to the processing unit. The cache memory is faster than the main system memory (RAM) and is designed to predict what data and program instructions will be needed next. The cache memory hierarchy includes L1, L2, and L3 caches, where L1 is closest to the CPU and is used for storing the microprocessor’s recently accessed information.
-
RAM: Random Access Memory (RAM) is a temporary storage bank used to store data so that it can be retrieved quickly. When a program is loaded into RAM, the CPU reads instructions and data from RAM and then processes them.
Process of running a program on a multicore CPU
The process of running a program on a multicore CPU involves the operating system (OS) loading the program into RAM, selecting the CPU execution context, and preparing the execution context (i.e., setting the contents of registers, program counter, etc.) before starting the trigger to execute instructions.
Now we understand what is a CPU and how it works, let us dive into the difference between CPU and GPU
GPU Hardware
A Graphics Processing Unit (GPU) is a specialized processor designed to handle the computational requirements of graphics and other highly parallelizable tasks. A cartoon diagram of Nvidai GPU is shown below:
The three main components of GPUs are:
-
ALUs and Tensor Cores: In NVIDIA GPUs, ALUs are the smallest units of processing that are grouped into cores. For example, each CUDA core in the A100 GPU consists of 32 ALUs, and there are 6912 CUDA cores in total. Additionally, NVIDIA has introduced Tensor cores in their latest Ampere architecture, which are specialized processing units that are particularly well-suited for Deep Learning workloads involving large matrix multiplications. Tensor cores can perform multiple operations per clock cycle, which is significantly faster than the one-operation-per-clock cycle performed by CUDA cores. With Tensor cores, computation is no longer the bottleneck; instead, the primary bottleneck is the speed at which data can be transferred to and from memory (Memory Bandwidth). Therefore, for Deep Learning workloads, it is preferable to have a GPU with Tensor cores.
-
Memory Bandwidth: Memory bandwidth is an often-overlooked metric in GPUs but is critical for performance. It refers to how quickly data can be moved between the memory (VRAM) and computation cores. If a GPU has poor memory bandwidth but excellent computation cores, the computation cores will be underutilized due to slower data transfer speeds. For instance, during the training of the BERT Large model, Tensor core utilization was only around 30%, meaning that Tensor cores sat idle for 70% of the time due to data availability delays. GPU memory bandwidth is the best indicator of performance, with the A100 GPU having 1,555 GB/s memory bandwidth compared to the V100’s 900 GB/s. Thus, a basic estimate of the A100’s speedup over the V100 is 1.73x. Overcoming bandwidth limits is a common challenge for GPU application developers.
-
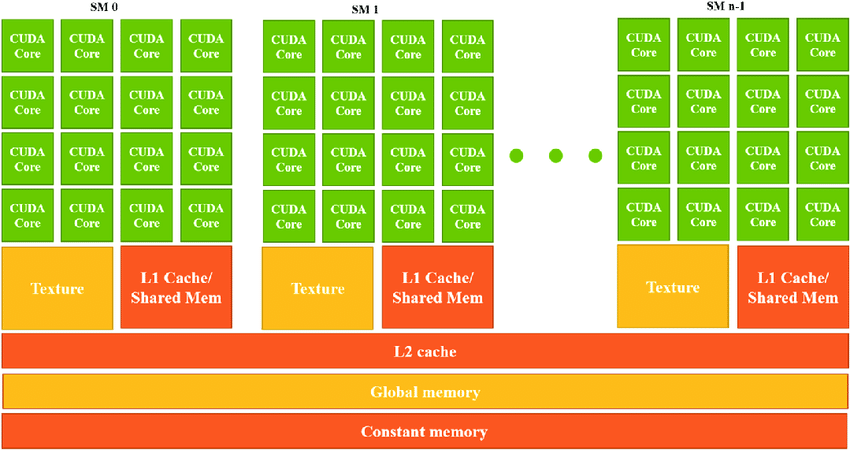
Shared Memory, L1 Cache Size, and Registers: Since memory bandwidth limits GPU performance, an efficient memory hierarchy is required to transfer data faster to the Tensor cores. The Ampere architecture optimizes the available memory bandwidth by implementing an improved memory hierarchy, from global memory to shared memory tiles, and finally to register tiles for Tensor Cores. In this way, the data transfer to and from the Tensor Cores is more efficient, allowing them to be utilized more effectively. Therefore, shared memory, L1 cache size, and registers are critical components in optimizing memory hierarchy and achieving maximum performance in Deep Learning workloads. A generic diagram of GPU memory hierarchy is as follows
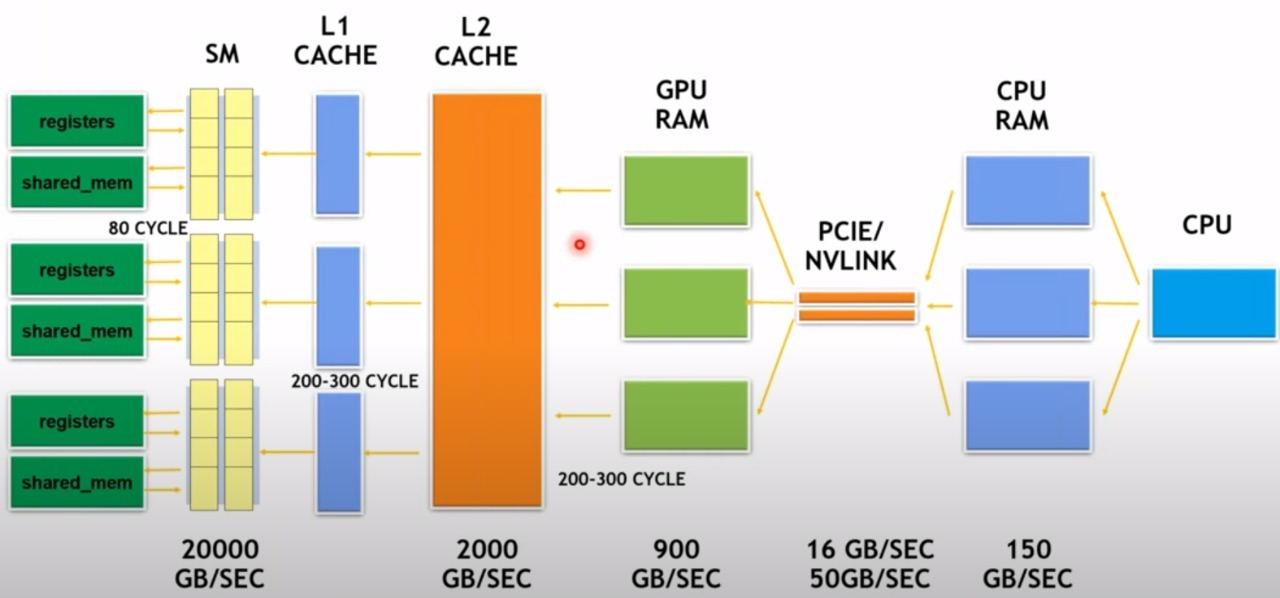
- We can see that the bandwidth amplifies as we move to left side, to the computing cores. Cache hierarchy reduces throughput demand on main memory
Process of running a program on a GPU
Prior 2007 (GPU)
If the task was to draw a picture using a GPU, the process would have been as follows:
- The application, through the graphics driver, provided the GPU with vertex and fragment shader program binaries.
- The application set graphics pipeline parameters, such as output image size.
- The application provided the GPU with a buffer of vertices.
- The GPU executed drawPrimitives(vertex_buffer) to render the image.
However, early GPU hardware could only execute graphics pipeline computations.
After 2007 (GP-GPU)
If the task was to run a computational workload on the GPU, the process would be as follows:
- The application allocated buffers in the GPU memory.
- The data was copied to and from the buffers.
- The application, through the graphics driver, provided the GPU with a single kernel program binary.
- The application instructed the GPU to run the kernel in a single program multiple data (SPMD) fashion by specifying the number of instances to run.
- The GPU launched the kernel using launch(myKernel, N).
Comparison: CPU vs GPU
Now we know about CPU and GPU hardware components. Let us do a quick comparison for both.
Characteristics of CPUs:
- ALUs
- CPUs have fewer (typically up to 40) but more complex cores compared to GPUs.
- These cores are designed to handle a variety of tasks, rather than specialized graphics processing.
- Control Units (CU)
- CPUs typically have a large number of control units.
- These control units are responsible for managing and executing a wide range of tasks, such as running the operating system and multiple applications simultaneously.
- Cache
- CPUs have large caches, typically measured in megabytes.
- The cache is a high-speed memory that allows the processor to access frequently-used data quickly, improving performance.
- If the required data is not in the cache, it can take much longer (around 100 clock cycles) to retrieve it from memory.
- Large caches help to minimize latency and optimize performance.
- Clock Speed
- CPUs typically have high clock speeds, measured in gigahertz (GHz).
- This is because CPUs are designed to handle a wide range of tasks, and their computations are typically single-threaded.
- Higher clock speeds can improve single-thread performance.
- RAM
- CPUs typically have access to a large amount of RAM, often measured in terabytes.
- RAM is a type of temporary storage that allows data to be accessed quickly, enabling many programs to be run simultaneously.
Characteristics of GPU:
- ALUs
- Large number of cores (e.g., 6912 tensor cores for A100)
- GPUs are designed to perform the same computation on multiple data items in parallel, which enables them to process vast amounts of data in a single workload.
- Compute units are based on SIMD hardware.
- Control Units
- Small number of units
- GPUs often perform similar tasks repeatedly (e.g., computing matrices or modeling complex numbers), so they do not require a large number of control units.
- Cache
- Small cache size (in KBs)
- GPUs prioritize computation power over cache, and therefore do not need a large cache.
- Clock speed
- Slower clock speed (in MHz)
- GPUs perform the same set of operations on data repeatedly, and therefore do not need a high clock speed.
- VRAM (Video RAM), device memory
- Large capacity (in GBs)
- Used to exchange data between the CPU and GPU
- Allocated and managed by the CPU
- Accessible to both the CPU and GPU
- Significantly larger than L1 and L2 cache registers
- Requires high bandwidth to facilitate data exchange between the CPU and GPU.
Quick summary: GPU vs CPU
CPU and GPU have different strengths and weaknesses. CPUs have very large main memory (RAM), fast clock speeds, and latency optimized via large caches. However, they have relatively low memory bandwidth and cache misses are very costly. In addition, CPUs have low performance/watt and low per thread performance each core runs at ~1 Ghz, which is 4 times slower than a GPU core.
On the other hand, GPUs have high bandwidth main memory, more compute resources (cores), and high throughput. They use data parallelism where the same instruction is applied to different data. However, GPUs have relatively low memory capacity, small caches, and run at slower clock speeds (MHz).
In summary, CPUs are designed for low latency and low throughput tasks, while GPUs are designed for high latency and high throughput tasks. CPUs use task parallelism, where multiple tasks map to multiple threads, while GPUs use data parallelism, where the same instruction is applied to different data.
Which GPUs to choose for Deep Learning?
I will cover this question in another detailed post, right now lets discuss briefly the facotrs to consider when choosing GPUs for ML Workloads. These factors are as follows:
- Tensor cores (explained previously)
- Memory bandwidth
- If we take the Tesla A100 GPU bandwidth vs Tesla V100 bandwidth, we get a speedup of 1555/900 = 1.73x
- Shared memory size
- For example, We have the following shared memory sizes on the following architectures:
- Volta: 96kb shared memory / 32 kb L1
- Turing: 64kb shared memory / 32 kb L1
- Ampere: 164 kb shared memory / 32 kb L1
Summary
In this post, we explored GPUs in-depth and gained a good understanding of their hardware architecture and the key differences between GPUs and CPUs. We also discussed the technical specifications that are important to consider when purchasing a GPU for machine learning workloads, such as tensor cores, memory bandwidth, and shared memory size. Additionally, we briefly touched on how to choose a GPU specifically for deep learning. In future posts, we will cover this topic in more detail.
References
- https://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf
- https://www.cs.cmu.edu/afs/cs/academic/class/15418-s18/www/lectures/06_gpuarch.pd
- http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
- https://ec.europa.eu/programmes/erasmus-plus/project-result-content/52dfac24-28e9-4379-8f28-f8ed05e225e0/lec03_gpu_architectures.pdf
- https://download.nvidia.com/developer/cuda/seminar/TDCI_Arch.pdf
- https://hdms.bsz-bw.de/frontdoor/deliver/index/docId/4500/file/gpgpu-origins-and-gpu-hardware-architecture.pdf
- https://www.cs.cmu.edu/afs/cs/academic/class/15418-s18/www/lectures/06_gpuarch.pdf
- http://www.irisa.fr/alf/downloads/collange/cours/ada2020_gpu_1.pdf
- https://homes.luddy.indiana.edu/achauhan/Teaching/B649/2011-Fall/StudentPresns/gpu-arch.pdf
- http://www.ziti.uni-heidelberg.de/ziti/uploads/ce_group/seminar/2014-Daniel_Schlegel-presentation.pdf
- https://www.control.lth.se/fileadmin/control/Education/DoctorateProgram/DeepLearning/2016/presentation.pdf
- https://www.nvidia.co.uk/docs/IO/147844/Deep-Learning-With-GPUs-MaximMilakov-NVIDIA.pdf
- https://repository.library.northeastern.edu/files/neu:m046sc381/fulltext.pdf
- https://www.comp.nus.edu.sg/~cs2100/2_resources/AppendixA_Graphics_and_Computing_GPUs.pdf
- http://www.compsci.hunter.cuny.edu/~sweiss/course_materials/csci360/lecture_notes/gpus.pdf
- https://www.cs.wm.edu/~kemper/cs654/slides/nvidia.pdf
- http://passlab.github.io/CSE436536/notes/lecture19_GPUArchCUDA01.pdf
- https://www.cs.utah.edu/~jeffp/teaching/MCMD/S20-GPU.pdf
- http://courses.cms.caltech.edu/cs101gpu/Old/2015_lectures/cs179_2015_lec05.pdf
- http://haifux.org/lectures/267/Introduction-to-GPUs.pdf
- https://www.nvidia.com/en-us/geforce/graphics-cards/compare/
- https://blog.paperspace.com/gpu-memory-bandwidth/
- https://www.cs.cmu.edu/afs/cs/academic/class/15418-s18/www/lectures/06_gpuarch.pdf